树链剖分
闲来无事,研究了一下这个神奇却又不算复杂的东西
什么是树链剖分:
顾名思义,树链剖分就是把一棵树剖成一条条的树链,再将树链存储为区间, 但实际操作中通常把所有的树链用一个区间存储
剖分的方法有几种,但用得多的还是重链剖分
重链剖分指的就是把某个结点与它的重儿子 (子树大小最大的子结点) 编成一条链
实现:
重链剖分是基于 dfs 的,所以也可以称之为一种” 启发式的 dfs 序”
重链剖分一般用两个 dfs 实现:
第一遍 dfs: 计算子树大小,寻找重儿子
伪代码:
1 | int dep[Mn],size[Mn],hs[Mn],fa[Mn]; //结点深度,结点子树大小,结点的重儿子,父结点 |
第二遍 dfs (重点部分): 记录每个结点的时间戳,把重儿子拉成链, 记录每个结点所在链的链顶 (即同一条链上深度最小的结点)
伪代码:
1 | int tp[Mn],a[Mn],visit_c[Mn],dfs_c(0); //链顶,dfs序,访问时间,计数器 |
树链剖分求 LCA:
几乎所有树上问题都要求 LCA, 所以求 LCA 是树链剖分的一项重要操作
树链剖分求 LCA 的方式略微有点像倍增 LCA
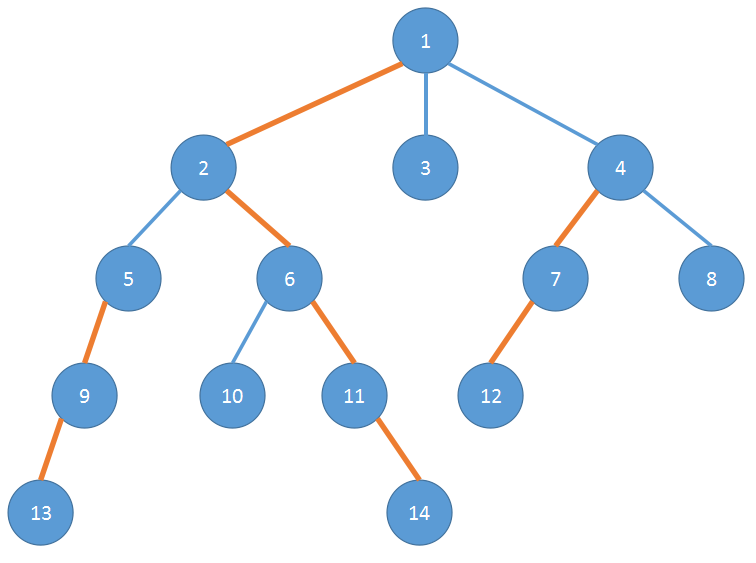
(橙色的边就是重链上的边)
方法就是如果两个结点不在同一条重链上时, 将链顶深度较大的那个结点跳到它所在的重链的链顶的父结点 , 直到这两个结点在同一条重链上,返回深度较小的那个结点
比如说要找这棵树的 LCA (13,10)
d (13)>d (10), 所以首先将 13 跳到 2
然后 d (2)<d (10), 将 10 跳到 6
此时 2 和 6 在同一条重链,返回深度较小的结点,所以 LCA (13,10)=2
这里有个重要的定理,是关于树链剖分的时间复杂度的:
若 v 是 u 的子结点,且 (u,v) 是轻边 (不在重链上的边), 则有 size (v)<size (u)/2
理由很简单,如果 size (v)>=size (u)/2 的话, 那么 size (v) 将会比 u 的任何一个儿子的 size 都要大, (u,v) 就是重边 (即在重链上的边) 了
由此可得一个推论: 对于任意一个非根节点 u, 在 u 到根节点的路径上, 轻边和重链的条数不超过 log2n, 因为每经过一条轻边 size 都会减半 (可以把这里的 size 看作可行范围)
所以,树链剖分 LCA 的时间复杂度是 O(log2n), 因为每个非根链顶与其父亲之间的边都是轻边
应用:
搞定树链剖分就可以在大多数树上问题上为所欲为啦~
只需要在求 LCA 的过程中顺便维护重链区间就好了
放几道例题来感受一下: