Compiler -- Parser
概述
语法分析将上一步生成的 token 流作为输入,通过定义的语法结构将其组织为解析树(parse tree)或更精简的抽象语法树(Abstract Syntax tree, abbr. AST)。由于语法分析器功能相较词法分析器更为强大,因此有些编译器可能会将词法分析的功能合并进语法分析器中。
虽然正则表达式被广泛用于各类字符串识别的场景,仍有相当一部分语言是无法用正则表达式表示的,例如括号的匹配和表达式的递归嵌套。因此需要一个更强大的工具来描述语法。在语法分析中通常使用上下文无关文法(Context-Free Grammar, abbr. CFG)来描述语法。
上下文无关文法
CFG 通常包括以下四个部分:
- 一组终止符(terminals),通常和 token 是一一对应的;
- 一组非终止符(non-terminals),通常一个非终止符代表了一个语法结构;
- 一个起始符,通常用 \(S\) 表示,属于非终止符;
- 一组产生式(productions),每个产生式包含一个箭头,左边是一个非终止符,右边是一个包含终止符或非终止符的一个序列。
为了方便书写,通常会将同一个非终止符为左式的产生式组织到一起,使用 | 将不同的右式分隔开来。例如对于一个仅包含加减法的算式,可以使用如下
CFG 描述(为方便起见这里的数字都只有一位):
1 | S -> S + dig |
对于一个 CFG,可以执行以下步骤:
- 从仅包含一个起始符 \(S\) 的串开始;
- 将任意一个串中的非终止符使用任意的以其为左式的产生式将其替换为产生式右边的串;
- 重复步骤 2 直至串中没有非终止符为止。
通过该步骤生成的所有串对应的 token 串即为该 CFG 接受的串,这个过程也被称为推导(derivation)。
推导的过程可以用树来表示。例如对于一个非终止符 \(A\),如果有产生式 \(A \to XYZ\),使用该产生式的推导过程可以用如下的树来表示:
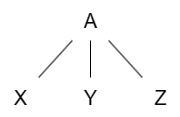
这样生成的树就叫做解析树。语法分析的目标便是分析给定的 token 串是否能被给定的 CFG 接受,并对接受的 token 串使用解析树来揭示其语法结构并进行处理。
解析树有以下特征:
- 树的根结点为起始符;
- 树的叶结点均为终止符(或者是空串符号 \(\epsilon\)),非叶结点都是非终止符;
- 若某个非叶结点 \(A\) 从左到右(注意顺序很重要)有子结点 \(X_1, X_2, \cdots, X_n\),则说明 CFG 有产生式 \(A \to X_1X_2 \cdots X_n\);
- 所有叶结点从左往右遍历即为原 token 串。
一个解析树可能由不同的推导过程而来,这主要是因为非终止符的展开顺序不同。最重要的两个是最左推导(left-most derivation)与最右推导(right-most derivation)。后面可以看到这两种推导顺序对应了两类不同的解析算法。
二义性
以之前所描述的仅包含加减法算式的 CFG 为例,如果没有对数字和算式进行区分:
1 | S -> S + S |
对算式 9-5+2 进行推导,可能生成两种不同的解析树:
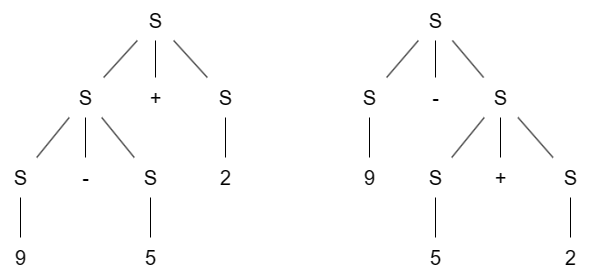
这种情况意味着语法中有歧义(ambiguity),因为两种解析树通常意味着同一个串的不同含义,可能会导致不确定的行为,因此需要消歧。
其中一种办法是手动重写语法使其不带歧义,例如之前定义的语法将数字与算式分开,这样将会生成类似与左边的解析树。另外一种办法是指定运算符的结合性(associativity)与优先级(precedence),例如指定加法与减法均为左结合则会生成左边的解析树,指定加法优先级大于减法则会生成右边的解析树。
语法制导翻译
通过在产生式的中间加入一些程序片段,我们可以利用解析树的结构来达成一些事情。例如,通过添加程序片段,下面的产生式将输出算式的后缀表达式:
1 | S -> S + dig { print('+') } |
这类在产生式中添加程序片段的 CFG 被称为语法制导翻译(Syntax-directed translation);其中的程序片段通常被大括号包裹起来,被称为语义动作(semantic actions)。有时解析树中的结点会带有 “返回值”,这些 “返回值” 被称为结点的属性(attribute)。
语法制导翻译并不需要建立解析树,只需要逻辑上按照后序遍历的顺序遍历解析树结点并执行其中的程序片段即可。也因此语法制导翻译可以用于建立解析树本身,但更通常的做法是建立抽象语法树。
抽象语法树
抽象语法树有时也简称为语法树。对于一个表达式,其抽象语法树(AST)的根结点代表了一个运算(operation),根的子结点代表了该运算的被操作树。例如对于上面的例子,生成的 AST 如下所示:
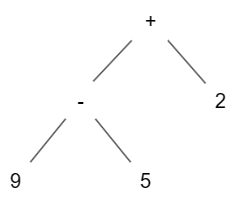
一般对于编程语言,所有语法结构基本都可以用运算与被操作数的结构来表示,因此总是可以建立 AST 来分析其中的语法与语义。
相较于解析树,AST 丢弃了一些仅有语法意义的 “助记符”,例如代表加号、括号的终止符等。相对于 “抽象”,解析树有时也被称为 “具体语法树”(concrete syntax tree)。
自顶而下解析
自顶而下解析(top-down parsing)也称递归下降解析(recursive decent parsing),是最简单的一种解析方法,具体步骤如下:
- 首先初始化一个全局的
next指针,指向 token 串的第一个 token 。然后调用一个与起始符 \(S\) 有关的函数S(); - 对于非终止符 \(E\),定义与其相关的函数
E(),记录下调用时next指针的位置,对 \(E\) 的所有产生式依次检查 token 串是否符合该产生式,每次检查前将next指针重置; - 对于终止符 \(t\),定义与其相关的函数
t(),若当前next指针指向的 token 与终止符对应的 token 一致则返回true并将next指针前移一位;否则返回false; - 对于每个产生式,依次调用右侧串符号对应的函数,若中间有函数返回
false则返回false,否则返回true。
可以看出对于每个产生式,自顶而下解析算法都是从左到右依次展开的,所以生成的推导是最左推导。
左递归
自顶而下解析并不适用于所有的 CFG,一个简单的例子是之前所定义的 CFG:
1 | S -> S + dig |
如果对该 CFG 使用自顶而下解析,则可能一直对非终止符 \(S\) 进行解析,导致无限递归。这种现象被称为左递归(Left Recursion)。消除左递归的方式是重写语法,例如如上的 CFG 可以重写为:
1 | S -> dig S' |
中间的 epsilon 用注释包起来了,这一行的意思是该非终止符接受空串。
另一种形式的左递归如下所示:
1 | S -> Aa | b |
这种非直接的左递归可以规约到直接的左递归语法:
1 | S -> Aa | b |
理论上所有的左递归语法都可以通过重写来得到等价的消除左递归语法,可以使用算法来自动消除左递归,但由于语法中可能存在语义动作,因此多数时候消除左递归是手动实现的。
左约分
另一种使用自顶而下解析算法可能产生的问题如下所示:
1 | S -> a | abS |
当遇到像 aba 这样的串时可能会提前返回从而导致解析失败。解决该问题的方法同样是重写语法:
1 | S -> aS' |
这种重写将相同左子串的多个产生式缩为一个产生式,称为左约分(left-factor)。
左约分同样可以使用算法自动处理,但基于相同的原因,多数时候消除左约分也是手动实现的。
LL (1) 解析
经过消除左递归与左约分,绝大多数语法都可以进行预测解析(predictive
parsing),即可以根据一部分输入的 token
与当前的解析树结点来确定当前应该执行的产生式。例如对于上面已经消除左递归的算式语法,可以建立如下的表格(这里将 dig 直接视为字符):
| dig | + | - | $ | |
|---|---|---|---|---|
| S | dig S' |
|||
| S’ | + dig S' |
- dig S' |
/*epsilon*/ |
该表行头一个非终止符,列头为一个
token,行列交界代表当处理某非终止符时遇到下一个 token
应该使用哪个产生式,$ 代表输入结束,空单元格代表该搭配不在语法中,是错误搭配。
像这样只使用一个 token 进行预测的称为 LL (1) 解析,如上的表称为 LL (1) 解析表,能够使用 LL (1) 解析的语法称为 LL (1) 语法。“LL (1)” 中第一个 “L” 代表 token 串从左往右扫描(Left to right),第二个 “L” 代表最左推导(Leftmost derivation),括号中的 “1” 代表仅使用一个输入 token 进行预测解析。
first 集与 follow 集
为了构建解析表,需要计算每个非终止符的 first 集与 follow 集。
first 集(用小写 \(f\) 表示)定义如下:
\[f(A) = \{t \mid A \to^* t\beta\} \cup \{\epsilon \mid A \to^* \epsilon\}\]
其中 \(t\) 为终止符,这个定义的意思即为若非终止符 \(A\) 可以推导出以 \(t\) 开头的串则 \(t \in f(A)\),当 \(A\) 可以推导出空串则 \(\epsilon \in f(A)\)。
对于 \(f(A)\),有:
\[ \begin{cases} t \in T \Rightarrow f(t) = \{t\} \\ \begin{cases} \exists A \to C\beta \\ \exists A \to B_1\cdots B_nC, \forall 1 \leq i\leq n, \epsilon \in f(B_i) \end{cases} & \Rightarrow f(C) \subseteq f(A) \\ \begin{cases} \exists A \to \epsilon \\ \exists A \to B_1\cdots B_n, \forall 1 \leq i\leq n, \epsilon \in f(B_i) \end{cases} & \Rightarrow \epsilon \in f(A) \end{cases} \]
其中大写的 \(T\) 代表终止符集合。利用这些定理可以计算出 first 集。
follow 集(用大写 \(F\) 表示)定义如下:
\[F(A) = \{t \mid S \to^* \beta At\gamma \}\]
这个定义的意思即为,若 \(t \in F(A)\),当且仅当从起始符 \(S\) 可以推导出一个串,串中 \(t\) 出现在 \(A\) 的正后方。一个与 first 集定义的区别是 \(\epsilon \notin F(A)\)。
对于 \(F(A)\),有:
\[ \begin{cases} \$ \in F(S) \\ \exists B \to \beta AC \Rightarrow (f(C)-\{\epsilon\}) \subseteq F(A) \\ \exists (B \to \beta AC \land \epsilon \in f(C)) \Rightarrow F(B) \subseteq F(A) \\ \end{cases} \]
其中美元符 $ 表示串终止符号。
有了这两个集合便可以构建预测解析表。令 \(M[A, t]\) 表示解析表 \(A\) 行 \(t\) 列的项,对于每个产生式 \(A\to\alpha\),做如下操作:
- \(\forall a \in f(\alpha)(a \neq \epsilon), M[A, a] = \alpha\)
- \(\epsilon \in f(\alpha) \Rightarrow \forall b \in F(A), M[A, b] = \alpha\)
若其中发生冲突则需要增加预测符数量,变为 LL (k)(k > 1) 语法。
错误恢复
有时我们希望编译器不要在只发现一个错误时就停下来,希望它尽可能地发现代码中的错误,因此需要编译器具有错误恢复(error recovery)的能力。
对于现代的编译器,通常有两种方法实现错误恢复:惊慌模式(panic mode)与错误产生式(error production)。
当使用惊慌模式遇到错误时,解析器会丢弃输入中的 token,直至遇到一个同步 token (synchronizing token),此时解析解析器得以从错误中恢复。一个常见的案例是指定语句的结束符号(例如分号)作为同步 token,这样当语句中出现错误时不会影响到后续语句的解析。
错误产生式则是直接为某些常见错误添加对应的产生式,例如初学者经常将 C
语言中的 5 * x 写为 5 x。
这样做的优点是可以根据指定的错误生成修复提示或直接修复错误,缺点是添加这类产生式将会使语法更难维护。
自底而上解析
不同于自顶而下解析,自底而上解析(bottom-up parsing)从叶结点开始向上构建解析树,通过规约(reduce)操作逆着产生式的方向将多个符号变为一个非终止符,最终规约到起始符。
通常来讲,自底而上解析能够适应的语法比自顶而下解析更多,但算法也更复杂,大多数时候自顶而下解析是手写的,而自底而上解析是由工具生成的,常见的工具有 yacc、 bison 等。
因此,如果我们从左到右扫描进行解析,则自底而上解析构建解析树的过程是逆向的最右推导,也因此这类解析称为 LR 解析。
对于该结论有一个重要的推论:假设在解析过程中生成了串 \(\alpha \beta \omega\),且下一步规约依照产生式 \(A \to \beta\),则串 \(\omega\) 中只存在终止符。因为如果将规约过程倒过来,\(\alpha A \omega \to \alpha \beta \omega\) 是最右推导中的一个步骤。
如果我们将符号串用竖线隔开,其左侧包含终止符与已规约的非终止符,右侧为尚未检测的终止符串,则可以通过如下两个操作进行解析:
- 移位(shift):将竖线往右移动一位(\(\alpha\mid\beta\omega\Rightarrow\alpha\beta\mid\omega\));
- 规约(reduce):若竖线左侧的右端子串符合要求则将其规约(\(\alpha\beta\mid\omega\Rightarrow\alpha A \mid\omega\))。
这类解析方法也称作移位 - 规约解析(shift-reduce parsing)。可以看出竖线左侧其实是一个栈。
句柄
要进行移位 - 规约解析,首先需要解决何时该进行规约的问题。一个朴素的想法是只进行那些能够最终规约到起始符的规约。
对于一个最右推导:
\[S \to^* \alpha A \omega \to \alpha \beta \omega\]
则称产生式 \(A \to \beta\) 与 \(\alpha\)(或称串 \(\alpha\beta\))为串 \(\alpha\beta\omega\) 的一个句柄(handle)。如果语法为有歧义的语法,则最右推导不止一个,一个串可能有多个句柄。
对于移位规约解析,由于产生的推导是最右推导,因此当进行了规约操作后,另一个句柄要么在栈顶(对应规约),要么需要右侧未检测的终止符(对应移位),因此句柄只会出现在栈顶,也因此规约也只应该在栈顶进行,分割的竖线不会向左侧移动。
冲突
一部分语法是不能使用移位 - 规约解析的,例如:
1 | S -> Sa | Sab | Sb | a |
当遇到 \(Sa \mid b\) 的情形时,移位和规约都可以产生有效的解析。像这样的情形称为移位 / 规约冲突(shift/reduce conflict)。
另一类冲突如下所示:
1 | S -> Sa | SE | a |
当遇到 \(Sa \mid b\) 的情形时,两种不同的规约方式都可以产生有效的解析。像这样的情形称为规约 / 规约冲突(reduce/reduce conflict)。
通常来讲,这类冲突是由于语法当中的歧义所导致的,需要通过重写语法或设定运算结合性和优先级来解决。通常移位 / 规约冲突比规约 / 规约冲突更好解决。例如一个简单的解决方法就是当遇到移位 / 规约冲突时总是使用移位。
LR (0) 自动机
虽然前面说明了句柄是什么以及句柄如何解决何时规约的问题,但并没有说明如何寻找句柄。为此需要定义可行前缀(viable prefix)的概念:
对于一个符号串 \(\alpha\),若存在串 \(\omega\),\(\alpha\mid\omega\) 为移位规约解析中的一个状态,则称 \(\alpha\) 为可行前缀。
称这个串为 “可行的” 是因为根据定义,可行前缀是句柄的一个前缀,也即只要当栈中的串为可行前缀,则总是有可能通过移位和规约得到句柄,从而成功解析。
对于可行前缀有一个重要结论:对于所有语法,可行前缀可以构成一个正则语言。
为了证明这个结论,需要定义 LR (0) 项(LR (0) item)(或简称项(item)):
一个 LR (0) 项是语法中一个产生式的某个前缀。
通常会使用 \(\cdot\) 分割产生式来表示一个项,例如对于一个产生式 \(A \to XYZ\),有四个 LR (0) 项:
\[\begin{aligned} A \to & \cdot XYZ \\ A \to & X\cdot YZ \\ A \to & XY\cdot Z \\ A \to & XYZ\cdot \\ \end{aligned}\]
特殊地,对于空串产生式 \(A\to\epsilon\) 只有一个项:\(A\to \cdot\)
在移位规约解析的过程中,栈中存储着许多不同的产生式前缀,形如:
\[p_1p_2 \cdots p_n\]
令 \(p_i\) 代表产生式 \(A_i \to \beta_i\) 的前缀,则:
- \(p_i\) 最终将规约为 \(A_i\);
- \(p_{i-1}\) 的剩余部分由 \(A_i\) 开始;
也即事实上可行前缀由若干的项组成,因此可以以项为状态,通过以下方式构建识别可行前缀的 NFA :
- 添加一条生成原来的起始符的产生式 \(S'\to S\);
- 对于每个形如 \(A\to \alpha \cdot B\beta\) 的项,添加一条边: \[ (A \to \alpha \cdot B\beta) \to^B (A \to \alpha B\cdot\beta) \]
- 对于对于每个形如 \(A\to \alpha \cdot B\beta\) 的项与产生式 \(B\to\gamma\),添加一条边: \[ (A \to \alpha \cdot B\beta) \to^\epsilon (B\to\cdot\gamma) \]
- 对于该 NFA,其初始状态为 \(S'\to\cdot S\),每个状态均为接受状态。
将其转化为 DFA 后,其中的每个 NFA 状态集合称为项的典范集(canonical collection of items),该 DFA 状态机称为 LR (0) 自动机(LR (0) automaton)。
对于自动机的构造,我们只需关心 DFA 结点中称为核(kernel)的那些项,也即起始项 \(S'\to \cdot S\) 还有那些分割符 \(\cdot\) 不在最左侧的项,因为显然其它的项是由 NFA \(\epsilon\) 规约而来。通过只存储核可以缩减 LR (0) 自动机的内存占用。
使用 LR (0) 自动机可以很方便地判断栈中的串是否为可行前缀,只需要使用栈中的串在自动机中遍历一遍即可。最终停下的状态代表栈顶可能的项。
SLR 解析
SLR 解析(Simple LR Parsing)使用 LR (0) 自动机,通过较为简单的规则来确定何时规约何时移位。
假设当前栈顶所在的 DFA 状态为 \(s\),下个输入的终止符为 \(t\), SLR 解析的规则为:
- 当项 \((A \to \alpha \cdot) \in s\) 且 \(t\in F(A)\)(大写 \(F\) 代表 Follow 集)时使用 \(A \to \alpha\) 进行规约;
- 当项 \((A \to \alpha \cdot t \omega) \in s\) 时进行移位;
- 若输入结束时项 \((S' \to S\cdot )\in s\),则接受该串;
- 若无法进行操作则报告错误。
同样的,如果某语法在 SLR 解析下没有冲突,则该语法属于 SLR 语法,否则不属于。
LR (1) 解析
在 SLR 解析中,我们做了一个 “启发式” 的假设,即当遇到的下一个符号属于规约产生式左项的 Follow 集时使用规约。但实际上有些语法并不一定适用这条假设。
解决这个问题的方法之一是我们对每个可能符号分别处理,在项中增加一个符号属性,当需要规约时检查该符号,如果与符号不匹配则不进行该规约。
像这样形如 \([A\to\alpha\cdot\omega, a]\) 的项称为 LR (1) 项。同样地,其中的 1 即代表项中的预测字符只有一个。
需要注意的是对于分割符 \(\cdot\) 不在最右侧的项来说,预测符是没有作用的。
创建 LR (1) 自动机只需要在创建 LR (0) 自动机的步骤中稍加改动即可:
- 对于每个形如 \([A\to \alpha \cdot B\beta, a]\) 的项,添加一条边: \[ [A \to \alpha \cdot B\beta , a] \to^B [A \to \alpha B\cdot\beta , a] \]
- 对于对于每个形如 \([A\to \alpha \cdot B\beta,a]\) 的项与产生式 \(B\to\gamma\),对于串 \(\beta a\) 的 first 集中的所有元素 \(b\in f(\beta a)\),添加一条边: \[ [A \to \alpha \cdot B\beta , a] \to^\epsilon [B\to\cdot\gamma , b] \]
- 对于该 NFA,其初始状态为 \([S'\to\cdot S , \$]\),每个状态均为接受状态;
- 将该 NFA 转为 DFA 即为 LR (1) 自动机。
同样地,DFA 状态中包含的 LR (1) 项集称为 LR (1) 项典范集;使用 LR (1) 自动机进行的解析称为 LR (1) 解析或者叫典范 LR (1) 解析。假设当前栈顶所在的 DFA 状态为 \(s\),下个输入的终止符为 \(t\),其规则如下:
- 当项 \([A \to \alpha \cdot , t] \in s\) 时使用 \(A \to \alpha\) 进行规约;
- 当项 \([A \to \alpha \cdot t \omega , b] \in s\) 时进行移位,其中的 \(b\) 为任意符号;
- 若输入结束时项 \([S' \to S\cdot, \$]\in s\),则接受该串;
- 若无法进行操作则报告错误。
LALR 解析
通常来讲 LR (1) 自动机的状态数量较大,不适合工程上使用,于是就有了 LALR 解析(LookAhead-LR parsing)。
相比于 SLR,LALR 自动机的状态数量与 SLR 相同,但能够解析更多的语法;相比于 LR (1),LALR 自动机的状态要少得多,能够解析的语法虽有缩减但能够满足绝大部分需要。因此 LALR 解析被广泛应用于各类自动工具中,如 yacc 和 bison。
通常,LR (1) 自动机中会包含许多 “核心(core)”,即 LR (1) 项的前面的 LR (0) 项部分相同的结点,一个想法是把这些结点合并起来。因为 LR (1) 自动机的边只与项中的 “核心” 有关(\(\epsilon\) 边转化为 DFA 后被去掉了),因此合并后之前连接的边也会合并。同时根据 LR (1) 自动机的构造规则,一个结点的 “核心” 与 LR (0) 自动机结点一一对应,因此 LALR 自动机的结点数量与 LR (0) 自动机相同且一一对应。
可以证明合并合并后的不会出现新的移位 / 规约冲突:合并后如果有出现移位 / 规约冲突则说明某个自动机结点内有项 \([A \to \alpha \cdot , a]\) 与 \([B \to \beta\cdot a\gamma , b]\)。由于合并只会合并 “核心” 相同的结点,则在原先的 LR (1) 自动机中,项 \([A \to \alpha \cdot , a]\) 所在的结点内必然有一个项 \([B \to \beta\cdot a\gamma , c]\),说明原来的 LR (1) 解析中具有相同的移位规约冲突。
但需要注意的是合并为 LALR 自动机后可能会出现新的规约 / 规约冲突,因此 LALR 语法是 LR (1) 语法的一个子集。
事实上生成 LALR 自动机并不需要真的合并 LR (1) 自动机的结点。通过之前的推导,我们可以通过扩展 LR (0) 自动机的方式,将预测符附在其中的 LR (0) 项上即可。同时根据之前的对 LR (0) 自动机的研究,这里只考虑对核附上预测符。
对于一个核项,有两种方式生成预测符:
- 自发:对于核项 \([A\to\alpha\cdot\beta, a]\),其所在的 LR (1) 自动机结点后继存在项 \([B\to\gamma\cdot\delta, b]\),且 \(b\) 与 \(a\) 无关,则称 \(b\) 是由项 \(B\to\gamma\cdot\delta\) 自发生成的(generated spontaneously);特别地,预测符 \(\$\)(输入终止符)由项 \(S'\to\cdot S\) 自发生成。
- 传播:同样对于核项 \([A\to\alpha\cdot\beta, a]\),其所在的 LR (1) 自动机结点后继存在项 \([B\to\gamma\cdot\delta, b]\),但 \(a=b\),其后继存在预测符 \(b\) 仅因为项 \(A\to\alpha\cdot\beta\) 也存在 \(b\) 作为附加的预测符。此时称预测符由 \(A\to\alpha\cdot\beta\) 传播(propagate)至 \(B\to\gamma\cdot\delta\)。注意传播本身与预测符无关,如果一个项传播至另一个项则其所有预测符均将附在被传播的项上。
事实上可以发现,两种生成方式的不同是由于 LR (1) 自动机生成规则中生成 \(\epsilon\) 边的规则导致的,串 \(\beta a\) 的不同情况导致了不同的生成方式:若 \(\epsilon\in f(\beta)\),则 \(a\in f(\beta a)\),此时便会产生传播;同时 \(f(\beta) \subseteq f(\beta a)\),此时 \(f(\beta)\) 的部分便是自发生成的预测符。
由于传播行为本身与预测符无关,因此我们可以使用一个不在语法中的终止符 \(\#\) 来分辨两种生成方式,具体来说:
- 对核项 \([A\to\alpha\cdot\beta, \#]\) 使用 LR (1) 自动机的生成规则生成其 \(\epsilon\) 闭包(也即只使用 \(\epsilon\) 边能到达的 LR (1) 项);
- 若项 \([B\to\gamma\cdot X\delta, a], a\neq\#\) 在闭包中,则在核项 \(A\to\alpha\cdot\beta\) 的 \(X\) 边的后继结点中,\(a\) 是 \(B\to\gamma X\cdot\delta\) 自发生成的(注意分割符的位置);
- 若项 \([B\to\gamma\cdot X\delta, \#]\) 在闭包中,则在核项 \(A\to\alpha\cdot\beta\) 的 \(X\) 边的后继结点中,\(A\to\alpha\cdot\beta\) 将预测符传播自 \(B\to\gamma X\cdot\delta\)。
最后使用两种附上预测符的方式将预测符附上即可建立 LALR 自动机:
- 生成 LR (0) 自动机以及其结点内的核;
- 使用上面的算法标记哪些预测符是自发生成,哪些项需要传播;
- 使用自发生成的预测符初始化核项;
- 传播预测符,直到最终没有新的预测符传播。
Lab
作业三需要使用 bison 生成 COOL 语言的 Parser。
首先需要定义各个非终止符所生成的 AST 类别:
1 | /* Declare types for the grammar's non-terminals. */ |
语法按照手册中给出的 CFG 写就行,唯一需要注意的是在 bison
中需要使用 error 来指定惊慌模式与同步 token:
1 | /* |
bison
语法中的 \$$ 表示非终止符的返回属性,$d 表示产生式中第
d 个符号的返回属性,生成 AST
结点的方法在手册以及对应的构造函数声明当中。
关于优先级我这里直接将优先级使用语法表示了,因此没有使用优先级定义。具体来讲,有关运算符的非终止符表示的不只是其本身,而是表示本 “层级” 以下的所有类型的表达式。